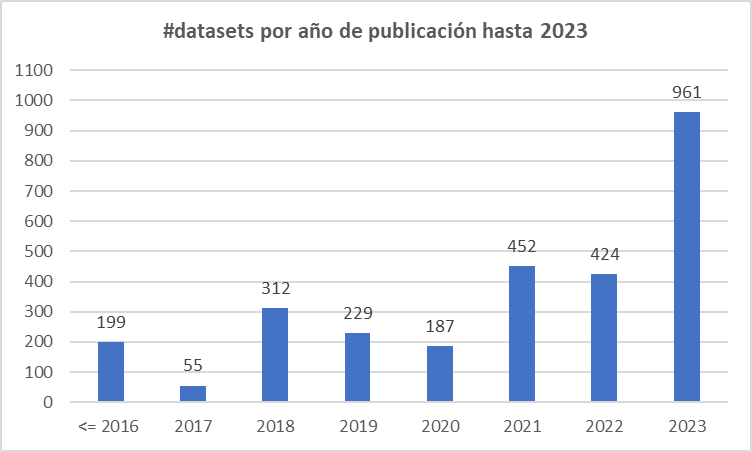
El informe Open Science: The Challenge for Universities, elaborado por la International Association of Universities (IAU), analiza el papel y los retos de las universidades en el nuevo paradigma de la Ciencia Abierta. Hoy vamos a prestar atención a dos de sus capítulos.
- Capítulo 2: papel de las universidades y fundamentos de la Ciencia. Este capítulo establece las bases del rol de las universidades en la generación y transmisión del conocimiento. Explica la interacción entre investigación y educación, el acceso al conocimiento global y cómo las universidades pueden aprovechar la ciencia para la innovación local y nacional. Se destaca la importancia de la integridad académica y la naturaleza de la ciencia como un proceso de autocrítica y corrección.
- Capítulo 3: retos actuales de las universidades. Aquí se identifican los desafíos clave para las universidades en la era de la Ciencia Abierta. Se abordan temas como la confianza en la ciencia, la diversidad epistemológica, el acceso a la información científica y los riesgos que enfrentan las universidades modernas. Se señala la influencia de la política y la economía en la investigación, así como las amenazas de la comercialización del conocimiento.
Ambos capítulos sirven como marco para comprender por qué las universidades son actores clave en la promoción de la Ciencia Abierta y cómo deben adaptarse para responder a los retos actuales.
El papel de las universidades
El resultado de la investigación es el nuevo conocimiento, mientras que la educación ayuda a formar nuevas personas. Ambos están interconectados: el nuevo conocimiento respalda la educación, y los estudiantes mejor formados contribuyen a la creación de conocimiento. El nuevo conocimiento proviene de los investigadores universitarios y de otros creadores de conocimiento, cuyas contribuciones combinadas generan un flujo global de conocimiento, principalmente a través de publicaciones.
El acceso libre a este flujo global de conocimiento es esencial para todos, tanto para investigadores como para estudiantes. Incluso para los equipos de investigación más avanzados, este flujo de conocimiento supera con creces sus contribuciones individuales. Las habilidades de los grupos de investigación les permiten explorar cómo aplicar mejor este conocimiento existente en la actividad docente y en la innovación en sus contextos locales o nacionales, además de inspirarlos a generar nuevas ideas científicas.
El conocimiento académico no solo beneficia a los investigadores, sino también a los estudiantes y a la sociedad en su conjunto como bien público. La interacción entre investigación y enseñanza en un entorno de debate racional y respetuoso es lo que crea el verdadero potencial de la universidad.
Las universidades poseen capacidades diversas y cumplen roles sociales específicos, ya sea con un enfoque internacional y de investigación intensiva, con un fuerte compromiso local, centradas en la educación o con vínculos estrechos con el tejido empresarial. Pueden especializarse en humanidades, ingeniería, medicina u otras disciplinas, o bien combinar varias de ellas. A pesar de su diversidad, todas las universidades que merecen ese nombre (muchas privadas no alcanzan los mínimos necesarios) comparten un mismo género: ser un espacio en el que expande el límite del conocimiento y la comprensión.
Desafíos contemporáneos para las universidades
3.1. Confiabilidad y confianza
La confiabilidad de la ciencia radica en la integridad de sus procesos. Existen prácticas que garantizan esta integridad a través de la revisión crítica y la exposición abierta de métodos de trabajo. Sin embargo, como ya hemos comentado en este blog, también hay pruebas crecientes de malas prácticas, negligencia e incluso fraude. Aunque la confiabilidad es vital, por sí sola no garantiza la confianza pública. Acciones populistas han desacreditado investigaciones y universidades, fomentando «hechos alternativos» en plataformas digitales. El escepticismo hacia la ciencia ha sido alimentado por la desinformación y el uso de la inteligencia artificial para manipular la opinión pública. La confianza en la ciencia y en las universidades es crucial para enfrentar estos desafíos.
3.2. Respeto a la diversidad
En la era de la Ciencia Abierta, las universidades deben reconocer, respetar y beneficiarse de la diversidad global de culturas, prácticas y prioridades. De lo contrario, este nuevo paradigma podría ser percibido como una extensión de un sistema dominado por los valores occidentales. Los rankings académicos refuerzan prioridades y metodologías predominantemente occidentales (o «norte global«), subvalorando el conocimiento desarrollado en otras regiones, en particular en el «sur global«, así como en saberes vocacionales, prácticos y artísticos. Es fundamental que las universidades promuevan una colaboración internacional basada en el aprendizaje mutuo en lugar de en relaciones de tutela o imposición.
3.3. Acceso al flujo global de conocimiento
El acceso a la información global es un activo esencial para la investigación y la docencia en las universidades. Sin embargo, algunas editoriales comerciales controlan este acceso, requiriendo pagos tanto para acceder como para publicar, lo que perjudica a las instituciones menos favorecidas económicamente. Este modelo limita la diversidad inclusiva de la Ciencia Abierta y perpetúa desigualdades en la generación y difusión del conocimiento.
3.4. Riesgos para la universidad moderna
La mayoría de las universidades públicas enfrentan presiones financieras (en España destacan los problemas de la universidades de Madrid y de Andalucía especialmente) que las llevan a priorizar actividades más rentables en detrimento de la experimentación y la investigación con beneficios a largo plazo. La dependencia de financiamiento gubernamental y privado (siempre escaso) puede generar restricciones en la difusión del conocimiento en favor de intereses económicos o nacionales a corto plazo. Además, la revolución digital y el avance de la inteligencia artificial han creado oportunidades y desafíos para las universidades. La cuestión es si las universidades serán capaces de aprovechar estas tecnologías para fortalecer la Ciencia Abierta o si, por el contrario, su papel será absorbido por corporaciones tecnológicas que privatizan el conocimiento a través de la inteligencia artificial y la propiedad intelectual.
El futuro de la universidad dependerá de su capacidad para equilibrar la presión financiera con su misión de fomentar el conocimiento, la inclusión y el progreso social, sin merma alguna en la calidad y la excelencia que, a pesar de todo, continu atesorando.