La Ciencia Abierta es una oportunidad excepcional para que las bibliotecas universitarias recuperen una posición de prestigio dentro de las comunidades académicas.
1. Relevancia renovada: La Ciencia Abierta, con su énfasis en el acceso abierto a la información y la transparencia en los procesos de investigación, coloca a las bibliotecas en el centro del ecosistema científico. Las bibliotecas pasan a ser actores clave para la gestión, difusión y preservación de datos, publicaciones y otros recursos científicos: Esto les ha de permtir recuperar un rol protagónico en la producción y el intercambio de conocimiento.
2. Nuevos servicios y habilidades: La Ciencia Abierta demanda innovar parte de los servicios que ofrecen estas bibliotecas. Estas deben estar situadas a la vanguardia en la gestión de datos de investigación, la creación de repositorios digitales, la formación en ciencia abierta y el asesoramiento a investigadores en temas como la publicación en acceso abierto y la gestión de las licencias y los derechos de autor. Al ofrecer estos servicios especializados, las bibliotecas se volverán a convertir en socios indispensables para la comunidad científica.
3. Mayor visibilidad e impacto: La participación activa en la Ciencia Abierta permite a las bibliotecas aumentar su visibilidad e impacto dentro de la universidad y la sociedad en general. Al facilitar el acceso al conocimiento científico y promover la transparencia en la investigación, las bibliotecas contribuyen a democratizar la ciencia y a mejorar la calidad de la investigación. Pero para esto se debe permanecer activo todo el año, no solo cuando llega la convocatoria de sexenios.
4. Colaboración y liderazgo: La Ciencia Abierta abre nuevas oportunidades para la colaboración entre las bibliotecas, los investigadores y otras instituciones. Las bibliotecas pueden liderar iniciativas en este campo a nivel institucional, regional e internacional, fortaleciendo su posición como agentes de cambio y promoviendo la innovación en el ámbito cientifico. Las bibliotecas pueden liderar la implementación de políticas de acceso abierto en todas sus instituciones, por ejemplo. Dentro de este punto podemos incluir el desarrollo del sistema de indentificación ORCID, liderado por las universidades de Oxford y Cambridge (obviamente hacen mucho más que competir en una regata) y que asigna identificadores únicos a los investigadores, facilitando la atribución y la interoperabilidad de la investigación a nivel mundial.
En resumen, la Ciencia Abierta es una oportunidad única para que las bibliotecas universitarias recuperen un rol protagónico en el ecosistema científico. Al adaptarse a las nuevas necesidades de la investigación y ofrecer servicios especializados, las bibliotecas pueden aumentar su visibilidad, impacto y relevancia dentro de las comunidades académicas. Este nuevo paradigma es una aliada estratégica para que las bibliotecas universitarias consoliden su papel como centros de conocimiento y motores de innovación en el ámbito científico. Y para que sean más valoradas por sus comunidades investigadoras.
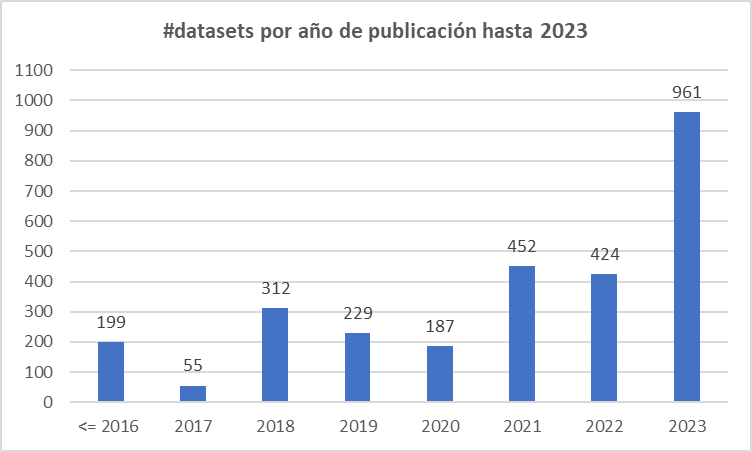
Durante el pasado año se publicaron 961 datasets en los repositorios de las universidades públicas españolas. Los datos, a excepción de la Universidade da Coruña y la Universidad de Las Palmas de Gran Canaria que remiten a su comunidad investigadora al repositorio comunitario ZENODO, los extraemos de los sitios web de cada universidad. También se han actualizado datos de alguna universidad de la que no pudimos extraer información hace un año y hemos levantado «el veto» que aplicábamos a una por usar software propietario en lugar de software libre para gestionar el repositorio. También se han actualizado los datos de los años anteriores porque, en algunos casos, se han detectado errores en los subtotales o pequeñas diferencias (como si se hubiera dado de baja algún ‘dataset’, algo que no debería de ocurrir habitualmente).
Los resultados son buenos, está claro que que se van notando los resultados del trabajo de REBIUN de y las directrices de la división de #CienciaAbierta de Fundación Española para la Ciencia y la Tecnología, FECYT en el aumento de la presencia de los conjuntos de datos de investigación en estos repositorios. Las bibliotecas universitarias públicas apoyan claramente el movimiento hacia la #CienciaAbierta: en un año en el que se han publicado más ‘datasets’ que el total de la suma de los dos inmediatamente anteriores, que ya marcaban máximos en la serie.
Casi el 75% de los nuevos ‘datasets’ han sido publicados por los consorcios autonómicos. Ese apoyo de la administración regional es muy adecuado y beneficioso y deberían tomar nota todas aquellas comunidades que tienen varias universidades públicas en sus territorios (Andalucía, Aragón, Valencia, etc.). Esta desproporción aún no se nota tanto en el total de ‘datasets’ publicados: 1693 por los consorcios frente a 1126 por las universidades que trabajan de forma indvidual.
Para tener una idea más global del nivel de publicación de #datasets de datos de investigación por parte de las universidades públicas españolas, habría que ampliar estos datos con el total de conjuntos publicados en Zenodo. En unos días tendremos más datos.
Cláudia Sofia Teixeira dos Santos presentó en enero de 2023 en la Universidade do Minho su tesis de máster ‘OGD Lens: avaliação automática da qualidade dos dados do European Data Portal’ sobre la evaluación de la calidad de los conjuntos de datos publicados en el portal de datos abiertos de la Unión Europea (sitio web aloja más de millón y medio de conjuntos de datos y 179 catálogos de datos puestos a disposición de la ciudadanía) para proporcionar una guía de mejora de su calidad. Para poder medir esa calidad desarrolló una metodología basada een los siguientes criterios:
Facilidad de uso con la que los usuarios pueden acceder a los datos y utilizarlos para fines de investigación.
La disponibilidad de los datos en un formato estándar y abierto y la accesibilidad de los conjuntos de datos a través de un repositorio en línea o una página web.
Calidad técnica: la precisión, integridad y consistencia de los datos.
Documentación: la información proporcionada junto con los datos, como la descripción de la fuente de los datos, las limitaciones de uso y la frecuencia de actualización.
Legalidad: la conformidad de los datos con las leyes de privacidad y derechos de autor.
Los metadatos empleados para describir los conjuntos de datos representan una valiosa fuente de información para satisfacer estos niveles de calidad. Por ello, la investigadora llevó a cabo un estudio empírico desarrollando un analizador semiautomático de evaluación de la información aportada por los metadatos en una serie de conjuntos de datos publicados. Los resultados obtenidos mostraron que la calidad de esos conjuntos varía significativamente. En líneas generales tienen una buena facilidad de uso, pero la calidad técnica, la documentación y la legalidad son aspectos que presentan deficiencias significativas.
En cuanto a la facilidad de uso, se dispone de buena información para el acceso a los datos y cómo reutilizarlos. En cambio, en cuanto a la calidad técnica, en muchos conjuntos de datos se carece de información sobre la fuente, las limitaciones de uso y la frecuencia de actualización. En lo relativo a la legalidad, muchos conjuntos no proporcionan información sobre los derechos de autor y la privacidad, lo que puede derivar en un uso inadecuado de los datos.
En este estudio se analizó la calidad de los catálogos y de los conjuntos de datos. Un catálogo de datos es un repositorio que contiene información detallada de los conjuntos de datos disponibles en una organización. Ofrece metadatos sobre los conjuntos de datos: descripción, origen, estructura, formatos, licencias, fechas de actualización. etc. También puede proporcionar información sobre cómo acceder y utilizarlos.
Y asoció a cada buena práctica la serie de beneficios que se derivaban de su uso. En la siguiente imagen podemos ver un fragmento de la tabla que construyó que afecta a las cinco primeras.
BP 4: Proporcionar información sobre la licencia de los datos
Reusabilidad Confiabilidad
BP 5: Proporcionar información sobre la procedencia de los datos
Reusabilidad Confiabilidad
Asociación de las DWBP (1 a 5) con sus beneficios de uso (Teixeira dos Santos, 2023, 26-27).
Nosotros hemos sintetizado esa vinculación en la siguiente tabla que nos permite concluir que la reusabilidad es el beneficio (y principio FAIR)l que agrupa a un número mayor de buenas prácticas seguido de la confianza.
Los principios FAIR datan del año 2106. Como todas las normas genéricas, dan lugar a distintas interpretaciones en su aplicación. Para remediar la proliferación de medidas del cumplimiento de estos principios (‘FAIRness’ en inglés), la ‘Research Data Alliance’ creó un grupo de trabajo para desarrollar un modelo de madurez en la implementación de los conjuntos de datos (2020).
Este modelo consiste en una serie criterios básicos de evaluación que establece indicadores y niveles de madurez asociados. En un principio, se elaboró un primer conjunto de directrices y una lista de verificación relacionada con la implementación de los indicadores, alineando así las directrices para evaluar el nivel de cumplimiento FAIR con las necesidades de la comunidad. Los indicadores se derivan, lógicamente de los principios FAIR y pretenden formular aspectos mensurables de cada principio que puedan ser utilizados por los enfoques de evaluación.
Los principios se toman tal cual; es decir, los indicadores no amplían o modifican los principios, sólo cubren aspectos que se mencionan en ellos o en aclaraciones adicionales. El planteamiento del modelo se basa en crear un indicador para cada aspecto distinguible en la descripción del principio. Así, cuando se habla de un identificador persistente y globalmente único, se definen dos indicadores: uno para evaluar la persistencia y otro para evaluar la unicidad.
Otra característica a destacar es que se definen indicadores distintos para los metadatos y para los datos, siempre que un principio se hable de «(meta)datos» y la evaluación del aspecto para los metadatos sea distinta de la evaluación para los datos. En la siguiente tabla se presenta un resumen del modelo basado en la lista de recomendaciones (fuente: https://zenodo.org/record/3909563).
Principio FAIR
Indicador
Propósito
Naturaleza
F1
RDA-F1-01M
Los metadatos se identifican mediante un identificador persistente
Esencial
RDA-F1-01D
Los datos se identifican mediante un identificador persistente
Esencial
RDA-F1-02M
Los metadatos se identifican mediante un identificador único global
Esencial
RDA-F1-02D
Los datos se identifican mediante un identificador único global
Esencial
F2
RDA-F2-01M
Se proporcionan metadatos enriquecidos para permitir la localización
Esencial
F3
RDA-F3-01M
Los metadatos incluyen el identificador de los datos
Esencial
F4
RDA-F4-01M
Los metadatos se presentan de forma que puedan ser recolectados e indexados.
Esencial
A1
RDA-A1-01M
Los metadatos contienen información que permite al usuario acceder a los datos.
Importante
RDA-A1-02M
Los metadatos pueden ser accedidos manualmente (por ejemplo, con intervención humana).
Esencial
RDA-A1-02D
Los datos pueden ser accedidos manualmente (por ejemplo, con intervención humana).
Esencial
RDA-A1-03M
El identificador de los metadatos resuelve un registro de metadatos.
Esencial
RDA-A1-03D
El identificador de los datos resuelve un objeto digital.
Esencial
RDA-A1-04M
Se accede a los metadatos a través de un protocolo estandarizado.
Esencial
RDA-A1-04D
Se accede a los datos a través de un protocolo estandarizado.
Esencial
RDA-A1-05D
Los datos pueden ser accedidos de forma automática (por ejemplo, por medio de un programa de ordenador).
Importante
A1.1
RDA-A1.1-01M
Los metadatos son accesibles a través de un protocolo de acceso libre.
Esencial
RDA-A1.1-01D
Los datos son accesibles a través de un protocolo de acceso libre.
Importante
A1.2
RDA-A1.2-01D
Los datos son accesibles por medio de un protocolo de acceso que soporta autenticación y autorización.
Útil
A2
RDA-A2-01M
Se garantiza que los metadatos seguirán disponibles después de que los datos dejen de estarlo.
Esencial
I1
RDA-I1-01M
Los metadatos usan representación del conocimiento expresada en formatos estandarizados.
Importante
RDA-I1-01D
Los datos usan representación del conocimiento expresada en formatos estandarizados.
Importante
RDA-I1-02M
Los metadatos utilizan una representación del conocimiento comprensible para las máquinas
Importante
RDA-I1-02D
Los datos utilizan una representación del conocimiento comprensible para las máquinas
Importante
I2
RDA-I2-01M
Los metadatos utilizan vocabularios conformes con los principios FAIR
Importante
RDA-I2-01D
Los datos utilizan vocabularios conformes con los principios FAIR
Útil
I3
RDA-I3-01M
Los metadatos incluyen referencias a otros metadatos
Importante
RDA-I3-01D
Los datos incluyen referencias a otros metadatos
Útil
RDA-I3-02M
Los metadatos incluyen referencias a otros datos
Útil
La evaluación de cada indicador se lleva a cabo estableciendo cinco niveles de cumplimiento de los principios:
0, no aplicable
1, aún no se está considerando
2, en estudio o en fase de planificación
3, en fase de implementación
4, totalmente implementado
Se ofrece la posibilidad de «descartar un indicador«, ya que este podría no ser relevante para una comunidad concreta. La razón de ser de este enfoque es dar crédito a la evolución y ayudar a mejorar la gestión de datos. Este enfoque puede ser muy útil para los proveedores y editores de datos que quieran hacer una prueba de autoevaluación y tener una idea más clara de dónde concentrar los esfuerzos para que sus conjuntos de datos satisfagan mejor los principios FAIR.
Como ejemplos de aplicación disponemos del caso de la Agencia Europea de Medio Ambiente (EEA) que ha utilizado el modelo para mejorar la calidad de sus datos alcanzando el nivel 2 de madurez (camino del siguiente nivel). La Universidad de California, Berkeley ha utilizado el modelo para mejorar la calidad de sus datos de investigación, alcanzando el mismo nivel de cumplimiento. Google ha utilizado el modelo para mejorar la calidad de sus datos de investigación llegando al nivel 3 de madurez.
El World Wide Consortium (W3C) publicó en 2017 el documento ‘Data on the Web Best Practices: W3C Recommendation‘ (DWBP), una detallada guía para el diseño, publicación y uso de datos enlazados en la web, con el objeto de promover su accesibilidad, interoperabilidad y reutilización.
Este documento proporciona orientación a los editores de datos en línea sobre cómo representarlos y compartirlos en un formato estándar y accesible. Las prácticas se han desarrollado para fomentar y permitir la expansión continua de la web como medio para el intercambio de datos. El documento menciona el crecimiento en la publicación de datos abiertos por parte de los gobiernos en todo el mundo, la publicación en línea de los datos de investigación, la recolección y análisis de datos de redes sociales, la presencia de importantes colecciones de patrimonio cultural y, en general, el crecimiento sostenido de los datos abiertos en la nube, destacando la necesidad de una comprensión común entre editores y consumidores de datos, junto con la necesidad de mejorar la consistencia en el manejo de los datos.
Estas buenas prácticas cubren diferentes aspectos relacionados con la publicación y el consumo de datos, como son los formatos, el acceso, los identificadores y la gestión de los metadatos. Con el fin de delimitar el alcance y obtener las características necesarias para implementarlas, se recopilaron casos de uso que representan escenarios de cómo se publican habitualmente estos datos y cómo se utilizan. El conjunto de requisitos derivados de esta recopilación se utilizó para guiar el desarrollo de las DWBP, independientes del dominio y la aplicación. Estas recomendaciones pueden ampliarse o complementarse con otros documentos de similar naturaleza. Si bien las DWBP recomiendan usar datos enlazados, también promueven el empleo de otros formatos abiertos como son CSV o json, maximizando más si cabe el potencial de este contexto para establecer vínculos.
CATEGORÍA
BUENA PRÁCTICA
Metadatos Requisito fundamental. Los datos no podrán ser descubiertos o reutilizados por nadie más que el editor si no se proporcionan metadatos suficientes.
BP 1: Proporcionar metadatos BP 2: Proporcionar metadatos descriptivos BP 3: Proporcionar metadatos estructurales
Licencias Según el tipo de licencia adoptada por el editor, puede haber más o menos restricciones a la hora de compartir y reutilizar los datos.
BP 4: Proporcionar información sobre la licencia de los datos
Procedencia El reto de publicar datos en la web es proporcionar un nivel adecuado de detalle sobre su origen.
BP 5: Proporcionar información sobre la procedencia de los datos
Calidad Puede tener un gran impacto en la calidad de las aplicaciones que utilizan un conjunto de datos.
BP 6: Proporcionar información sobre la calidad de los datos
Versiones Los conjuntos de datos pueden cambiar con el tiempo. Algunos tienen previsto ese cambio y otros se modifican a medida que las mejoras en la recogida de datos hacen que merezca la pena actualizarlos.
BP 7: Proporcionar un indicador de versión BP 8: Proporcionar el historial de versiones
Identificadores El descubrimiento, uso y citación de datos en la web depende fundamentalmente del uso de URI HTTP (o HTTPS): identificadores únicos globales.
BP 9: Utilizar URIs persistentes como identificadores de conjuntos de datos BP 10: Utilizar URIs persistentes como identificadores dentro de conjuntos de datos BP 11: Asignar URIs a versiones y series de conjuntos de datos
Formatos El mejor y más flexible mecanismo de acceso del mundo carece de sentido si no se sirven los datos en formatos que permitan su uso y reutilización.
BP 12: Utilizar formatos de datos estandarizados legibles por máquina BP 13: Utilizar representaciones de datos neutras respecto a la localización BP 14: Proporcionar datos en múltiples formatos
Vocabularios Se utiliza para clasificar los términos que pueden utilizarse en una aplicación concreta, caracterizar las posibles relaciones y definir las posibles restricciones en su uso.
BP 15: Reutilizar vocabularios, preferentemente estandarizados BP 16: Elegir el nivel adecuado de formalización
Acceso a los datos Facilitar el acceso a los datos permite tanto a las personas como a las máquinas aprovechar las ventajas de compartir datos utilizando la infraestructura de la red.
BP 17: Proporcionar descarga masiva BP 18: Proporcionar subconjuntos para conjuntos de datos grandes BP 19: Utilizar negociación de contenidos para servir datos disponibles en múltiples formatos BP 20: Proporcionar acceso en tiempo real BP 21: Proporcionar datos actualizados BP 22: Proporcionar una explicación para datos que no están disponibles BP 23: Hacer datos disponibles a través de una API BP 24: Utilizar estándares web como base de las APIs BP 25: Proporcionar documentación completa para su API BP 26: Evitar cambios que rompan su API
Preservación Las medidas deben tomar los editores para indicar que los datos se han eliminado o archivado.
BP 27: Preservar identificadores BP 28: Evaluar la cobertura del conjunto de datos
Retroalimentación (‘feedback’) Ayuda a los editores en la mejora de la integridad de los datos, además de fomentar la publicación de nuevos datos. Permite a los consumidores de datos tener voz describiendo experiencias de uso.
BP 29: Recopilar comentarios de los consumidores de datos BP 30: Hacer comentarios disponibles
Enriquecimiento Procesos que pueden utilizarse para mejorar, perfeccionar los datos brutos o previamente procesados. Esta idea y otros conceptos similares contribuyen a hacer de los datos un activo valioso para casi cualquier negocio o empresa moderna.
BP 31: Enriquecer datos generando nuevos datos BP 32: Proporcionar presentaciones complementarias
Republicación Combinar datos existentes con otros conjuntos de datos, crear aplicaciones web o visualizaciones, o reempaquetar los datos en una nueva forma.
BP 33: Proporcionar comentarios al editor original BP 34: Seguir los términos de la licencia BP 35: Citar la publicación original
Resumen de las Data Web Best Practices del W3C
Beneficios e incovenientes de las DWBP
Como podemos ver, se trata de unas pautas que precisan de cierto volumen de trabajo y muchas han de ser aplicadas por personas con mucha experiencia. A continuación, resumimos los beneficios y los (posibles) inconvientes de las mismas.
Beneficios:
Interoperabilidad: Las prácticas están diseñadas para asegurar que los datos publicados sean comprensibles y accesibles para una amplia variedad de aplicaciones y sistemas. Esto facilita la integración y el intercambio de datos entre organizaciones y plataformas.
Reutilización: Si se siguen las buenas prácticas, los datos se estructuran coherentemente y se proporcionan metadatos claros. Esto facilita la reutilización de los datos por parte de otros usuarios y organizaciones para crear nuevas aplicaciones, servicios o análisis. Esto fomenta la innovación y la creación de valor.
Calidad de los datos: Las buenas prácticas promueven la calidad de los datos al definir estándares para la representación y la semántica de los datos. Esto reduce los errores y las ambigüedades en los datos publicados, mejorando la confiabilidad y la precisión de la información.
Accesibilidad: Un seguimiento de las buenas prácticas asegura que los datos estén disponibles y sean accesibles para un público amplio, incluyendo personas con discapacidades. Esto promueve la inclusión y garantiza que los datos estén disponibles para todos los usuarios, independientemente de sus necesidades.
Indexación y búsqueda: Los motores de búsqueda comprenden mejor e indexan más eficazmente los datos que siguen las DWBP. Esto mejora su encontrabilidad, aumentando la visibilidad de los datos en los resultados, lo que aumenta su alcance y utilidad.
Transparencia: Publicar datos según estándares abiertos y transparentes, se promueve la transparencia y la rendición de cuentas. Esto es especialmente importante en los datos de las administraciones públicas y también en datos científicos, donde la accesibilidad a los conjuntos de datos es esencial para la toma de decisiones informadas y la supervisión.
Facilita la colaboración: Estas buenas prácticas fomentan la colaboración entre organizaciones y comunidades al proporcionar un marco común para compartir datos. Esto es especialmente útil en proyectos de colaboración donde múltiples partes necesitan compartir y trabajar con datos de manera eficiente.
Posibles inconvenientes
Coste: Implementar las DWBP puede requerir inversiones significativas en recursos humanos y tecnológicos, lo que es un problema para organizaciones con presupuestos limitados.
Complejidad: Algunas de las mejores prácticas del W3C resultan técnicamente complejas de implementar, especialmente para personas u organizaciones sin experiencia previa en estándares web y tecnologías relacionadas.
Cumplimiento: Asegurarse de cumplir con todas las directrices y recomendaciones puede ser un desafío, y el incumplimiento podría afectar la efectividad de la publicación de datos.
Adopción: No todas las organizaciones y comunidades pueden estar dispuestas o capacitadas para adoptar estas prácticas de inmediato. Esto puede limitar la interoperabilidad y la reutilización de datos.
Seguridad y privacidad: La publicación de datos ha de hacerse con precaución para evitar la divulgación de información sensible o privada. El cumplimiento de las normativas de protección de datos es esencial y requiere un esfuerzo adicional.
Actualización continua: Mantener los datos actualizados y en conformidad con las buenas prácticas puede ser un verdadero desafío a largo plazo. Esto va a precisar de dedicación y recursos continuos.
En resumen, publicar datos siguiendo las Data Web Best Practices del W3C ofrece numerosos beneficios en términos de interoperabilidad, reutilización de datos, calidad de datos, accesibilidad y transparencia. Sin embargo, también conlleva inconvenientes relacionados con el costo, la complejidad, el cumplimiento, la adopción, la seguridad y la privacidad, así como la necesidad de mantener los datos actualizados. Seguir estas mejores prácticas va a depender de los objetivos y recursos de la organización y de su compromiso con la calidad y la accesibilidad de los datos a publicar.
En otras entradas seguiremos hablando de buenas prácticas y conjuntos de datos, algo preciso para llegar a la Ciencia Abierta.
Los méritos que los investigadores queramos ver reconocidos en la Convocatorio de Sexenios de CNEAI y que hayan sido publicados desde 2011, deben ser depositados en repositorios institucionales o temáticos (si no lo están ya).
Comienzan a notarse algunos cambios impuestos por la LOSU. De confirmarse lo indicado en el borrador de criterios que han sido expuestos a consulta pública, de acuerdo con su artículo, 12 en todos los campos se requerirá el depósito en repositorios institucionales o temáticos de acceso abierto de las publicaciones científicas, conjuntos de datos, códigos y metodologías que se sometan a evaluación, incluyendo un identificador persistente (DOI, Handle, o similar), a fin de alcanzar los objetivos de investigación e innovación responsables y de libre circulación de los conocimientos científicos y las tecnologías que promulgan las políticas europeas de ciencia abierta.
Así, en el caso de las publicaciones seriadas o periódicas, se recuerda a las personas solicitantes que, desde la entrada en vigor de la LCTI, el 2 de diciembre de 2011, el personal de investigación cuya actividad investigadora esté financiada mayoritariamente con fondos públicos hará pública la versión final aceptada para publicación en repositorios institucionales o temáticos de acceso abierto (artículo 37 de la LCTI, en su versión previa a la Ley 17/2022). Este precepto, reforzado ahora en los artículos 12.2 y 12.3 de la LOSU, será por tanto de aplicación para las publicaciones presentadas con fecha 2011 o posterior, excepto en el caso de otros formatos de publicación como las monografías.
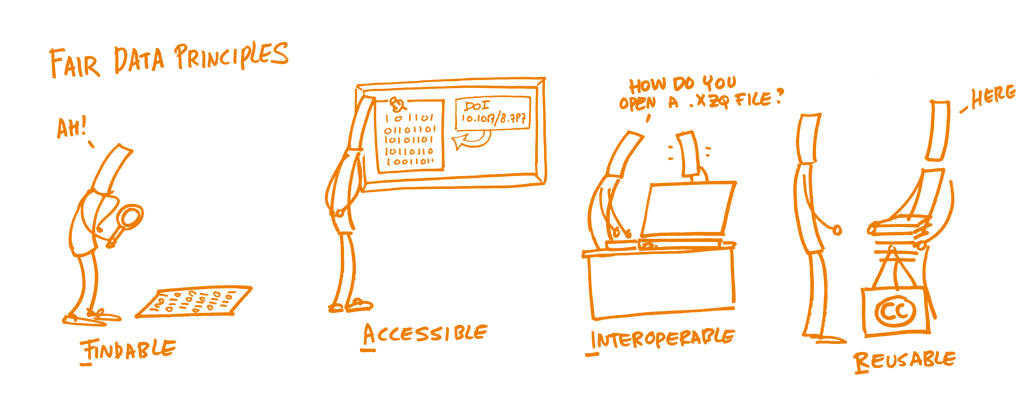
Principios FAIR
Además, el vigente artículo 37 de la LCTI, tras su modificación por la Ley 17/2022), añade que se deberá depositar una copia de la versión final aceptada para publicación y los datos asociados a las mismas en repositorios institucionales o temáticos de acceso abierto, de forma simultánea a la fecha de publicación, siendo este precepto de aplicación para las publicaciones presentadas con fecha 2022 o posterior. Asimismo, de acuerdo con el citado artículo 37 de la LCTI y el artículo 12.5 de la LOSU, los conjuntos de datos que se sometan a evaluación, con fecha 2022 o posterior, deberán cumplir con los principios FAIR (fáciles de encontrar, accesibles, interoperables y reutilizables) y, siempre que sea posible, se difundirán en acceso abierto en repositorios o infraestructuras de datos de confianza.
En el caso de las aplicaciones informáticas, se valorará que sean desarrolladas según los principios de colaboración abierta del software libre y publicadas bajo la Licencia Pública de la Unión Europea o licencias compatibles
Si internet posee actualmente el nivel de desarrollo y popularización tan alto es debido, sin duda alguna, al interés que despertó entre algunos políticos de primer nivel a principios de los años 90. Se ha hablado mucho (y con razón) de la trascendencia de la información y de la necesidad de disponer de una adecuada gestión de la misma como recurso vital para el desenvolvimiento de las organizaciones en el contexto actual: la Sociedad de la Información(entorno que ya aventuraba el sociólogo japonés Yoneji Masuda como: ‘sociedad que crece y se desarrolla alrededor de la información y aporta un florecimiento general de la creatividad intelectual humana, en lugar de un aumento del consumo material» (‘The information society as post-industrial society‘, 1981).
Yoneji Masuda
Yoneji Masuda fue un eminente sociólogo japonés, fallecido en 1995, cuya actividad profesional y académica tuvo una importancia decisiva en la definición estratégica de un modelo de sociedad tecnológica para Japón impulsado desde las políticas públicas. Al tiempo, fue uno de los pioneros en la conceptualizar la idea de Sociedad de la Información. Trabajó en diversos programas de los ministerios de Trabajo y Educación japoneses destinados a mejorar y racionalizar las prácticas de producción y formación de la población. Fue director del Instituto para el Desarrollo de los Usos de los Computadores en Japón y fundador y presidente del Instituto para la Informatización de la Sociedad, profesor de la Universidad de Aomuri y director de la Sociedad Japonesa de Creatividad. A partir de un informe del Ministerio de Industria y Comercio (MITI) elabora para el Instituto JACUDI un plan para la Sociedad de la Información como «objetivo nacional para el año 2000«.
Alegoría de la Sociedad de la Información (dibujada por Dalle 3 – chat GPT).
Cuando DARPA deja de ser el principal soporte financiero, el proyecto de internet se desarrolló en esta década al amparo de otras organizaciones financiadoras, destacando entre todas enormemente la NSF (‘National Science Foundation’, agencia del gobierno de EEUU independiente del Departamento de Defensa que impulsa investigación y educación fundamental en todos los campos no médicos). En esa época llegó a establecerse un altísimo vínculo entre los ordenadores de su propia red y los que procedían de la originaria Arpanet. De esta forma surge la declaración RFC 985 (‘Request for comments» o «Requisitos para pasarelas de Internet», serie de notas sobre la red y sobre sistemas que se conectan a internet, que comenzaron a publicarse en 1969) que formalmente aseguraba la interoperabilidad entre las partes de la red y establecía los mecanismos necesarios para asegurar y facilitar la incorporación de nuevas redes.Tanto NSF como otras agencias financiaban los costes de la infraestructura común, incluidos los circuitos transoceánicos destinados a dar acceso a la red a comunidades científicas de otras partes del mundo. Al mismo tiempo surgió el interés de organizaciones privadas de hacer uso de la red, infraestructura que hasta entonces había estado dedicada de forma exclusiva a usos educativos y de investigación. Hacia el año 1988 se comienza a hablar de la necesidad de disponer de una infraestructura nacional de redes que permitierse ese uso conjunto y justo en todo momento.Esta iniciativa llama la atención de Al Gore (senador entonces y después vicepresidente de los EEUU, ahora Premio Nobel de la Paz por su labor en defensa del Medio Ambiente) quien propició la elaboración de la iniciativa NII (siglas en inglés de ‘National Information Infrastructure’).
Al Gore cuando era vicepresidente USA
NII era una propuesta de red avanzada y perfecta de las redes de comunicaciones públicas y privadas, servicios interactivos, de hardware y software interoperable, computadoras, bases de datos y electrónica de consumo a poner una gran cantidad de información al alcance de los usuarios). En este documento y (casi seguramente) por primera vez hallamos un texto político que habla del valor estratégico de la información en el contexto actual, basando su éxito en el desarrollo de una infraestructura de telecomunicaciones de alcance mundial que promoviera el uso de internet en todos los ámbitos.
Más o menos en la misma época, la Unión Europea redactaba un documento similar en la línea de desarrollar un acceso global a la red y a desarrollar un mercado de servicios y productos alrededor de la misma. Este documento es conocido como el «Informe Bangemann» (1994) donde el excomisario europeo Martin Bangemann afirmaba:
«cuya principal meta ha sido acelerar la instauración de un mercado mundial abierto y «autoregulado». Política que ha contado con la estrecha colaboración de organismos multilaterales como la Organización Mundial del Comercio (OMC), el Fondo Monetario Internacional (FMI) y el Banco Mundial, para que los países débiles abandonen las regulaciones nacionales o medidas proteccionistas que «desalentarían» la inversión; todo ello con el conocido resultado de la escandalosa profundización de las brechas entre ricos y pobres en el mundo».
Informe Bangemann
A pesar de esta visión tan economicista y neoconservadora, el propio autor reconocía que las TIC eran un factor clave en la aceleración de la globalización económica porque su imagen está más asociada a aspectos más «amigables» de este proceso, como internet, telefonía celular e internacional, TV por satélite, etc. Así, la Sociedad de la Información ha asumido la función de «embajadora de buena voluntad» de la globalización, cuyos beneficios» podrían estar al alcance de todos/as, si solamente si pudiera estrechar la brecha digital«.
El siguiente paso en la evolución de internet fue la introducción en la red de un protocolo de comunicaciones (conjunto de reglas y procedimientos que regulan las comunicaciones telemáticas) global, robusto y eficaz para hacer posible la sencilla conexión de nuevos hosts y de nuevas redes independientes. En su primera implementación, Arpanet disponía de un protocolo “host a host” de manera que había que modificarlo según las características de los diferentes equipos informáticos que pretendieran incorporarse a ella.
Entonces, los ordenadores eran bastante incompatibles unos con otros e incluso a nivel interno manejaban distintos códigos para la representación de la información (ASCII, EBCDIC, etc.). Por tanto, no se trataba únicamente de conectar equipos, sino de conseguir que pudieran dialogar entre ellos y compartir información de manera comprensible. Este inmenso trabajo, unido al rápido crecimiento de la red, hizo inviable continuar con la conexión «punto a punto» y propició el desarrollo de una nueva familia de protocolos de comunicaciones.
Surge así un nuevo paradigma: la interconexión de sistemas abiertos (‘internetworking‘), de manera que equipos informáticos de distinta naturaleza pudieran compartir datos y aplicaciones dentro de un entorno abierto de comunicaciones.
ASCII (‘American Standard Code for Information Interchange’ – Código Estándar Estadounidense para el Intercambio de Información). Código de caracteres basado en el alfabeto latino creado en 1963 por el Comité Estadounidense de Estándares (conocido desde 1969 como Instituto Estadounidense de Estándares Nacionales, o ANSI) como refundición o evolución de los conjuntos de códigos usados entonces en telegrafía. En 1967, se incluyeron las minúsculas, y se redefinieron códigos de control para formar el código US-ASCII.
EBCDIC (acrónimo de ‘Extended Binary Coded Decimal Interchange Code’) es un código estándar de 8 bits usado por computadoras mainframe IBM, la empresa que adaptó el EBCDIC del código de tarjetas perforada en los años 1960 y lo promulgó como una táctica customer-control cambiando el código estándar ASCII.
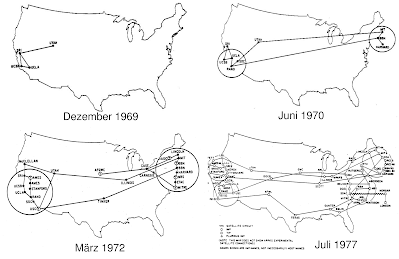
Crecimiento de Arpanet en su primera década
Esta idea nace en contraposición a los sistemas propietarios (o cerrados), típicos de la época cuyo paradigma lo representaba perfectamente la familia de ordenadores IBM S/360, sistemas donde tanto el hardware como el software eran específicos y propiedad del fabricante y existían muchísimos problemas, tanto técnicos como económicos, para hacerlos compatibles con otros equipos (además, como la empresa IBM era el “gigante informático” de la época, con un nivel de dominio superior incluso al que ha llegado a tener Microsoft, el mercado se veía muy condicionado por sus sistemas y tecnologías).
Frontal de un ordenador IBM 360.
El IBM 360 fue el primer ordenador en usar microprogramación. Con su introducción en el mercado se creó el concepto de arquitectura de familia que consistió en 6 ordenadores que podían hacer uso del mismo software y los mismos periféricos. El sistema también hizo popular la computación remota, con terminales conectados a un servidor, por medio de una línea telefónica. El IBM 360 es uno de los primeros ordenadores comerciales que usó circuitos integrados, y podía realizar tanto análisis numéricos como administración o procesamiento de archivos. Se considera que la tercera generación de computadoras comenzó con su introducción. Estos modelos comenzaron a ser retirados a partir del año 1977 (aunque no era raro verlos operativos en la década de los 80, y más fuera de Estados Unidos, donde igual acababan de «llegar»).
Khan y Cerf hoy en día
La solución a la incompatibilidad entre equipos conectados a una misma red pasaba por definir una arquitectura de comunicaciones en la que, en forma de niveles o capas, se planteara la resolución de los problemas por medio de unas funciones que desarrollan distintos protocolos de comunicaciones. Bajo esta perspectiva se define un nivel de “interconexión” superior al nivel de “intrared”. Así, los equipos trabajan a nivel local según las características de su sistema operativo y luego operan a nivel de red bajo nuevas reglas, formatos y procedimientos especificados por un protocolo de red con vocación de sistema abierto. En el caso de internet ese protocolo de comunicaciones es el TCP/IP (‘Transmission Control Protocol/Internet Protocol’), propuesto y desarrollado por dos de los ingenieros más importantes en la historia de la red: Vinton Cerf y Robert Khan (1974).
TCP/IP es en realidad una familia de protocolos donde TCP es el encargado del control del flujo de datos y de la transmisión segura por la red de los paquetes de datos e IP de la identificación de origen y destino de la transmisión y del adecuado direccionamiento de los paquetes de datos (se corresponden con los niveles 3 y 4 del Modelo OSI de interconexión de sistemas abiertos).DARPA (la siguiente denominación de ARPA, en la que ya se incluçó la palabra «Defense») financió la implementación de este protocolo y, en poco tiempo, existieron versiones independientes que podían interoperar.
Esquema general del protocolo TCP/IP
Al principio, todos estos desarrollos se realizaban conectando grandes equipos informáticos (aún no se había popularizado el ordenador personal). Por ello, se desarrollaron versiones más sencillas y compactas que dieron fruto a dos implementaciones: la del PARC de Xerox y otra, la que resultó más trascendente (al menos para el gran público), para el PC de IBM, consiguiéndose que los ordenadores personales también pudieran convertirse en hosts de ARPANET sin necesidad de formar parte de otras redes más grandes: con esto se había dado un paso definitivo hacia la interconexión global.
Ordenador personal de IBM con monitor en color.
El IBM Personal Computer, fue el ordenador que lo cambió todo. Introducido en agosto de 1981 y creado por el equipo del IBM Entry Systems Division. Junto al «microcomputador» y al «computador casero», el término «computador personal» ya estaba en uso antes. Se empleó en 1972 para caracterizar al Alto de Xerox PARC, pero el éxito de IBM hizo que PC equivaliese al microcomputador compatible con sus productos. El grupo de trabajo reunido para desarrollarlo decidió que el sistema operativo viniera de vendedores externos. Esta ruptura con la tradición de la compañía (siempre habían apostado por desarrollos internos), se llevó a cabo para ahorrar tiempo. Microsoft fue la empresa seleccionada como fabricante del sistema operativo: el PC-DOS (MS-DOS si la máquina no era de IBM como ocurrió al poco tiempo). En pocos años, esta decisión se vio claro que esta decisión fue el mayor error estratégico de la empresa, básicamente porque propició el lanzamiento de otro gigante informático: la empresa de Bill Gates, Steve Pallmer y Paul Allen: Microsoft. Curiosamente, en la misma época, incluso un poco antes, Steve Wozniak y Steve Jobs lanzaban el Apple II, la primera serie de microcomputadores de producción masiva a través de otro gigante actual de la informática: Apple Computer, pero este avance quedó un poco «escondido» por la trascendencia del IBM PC.
‘Floppys’ (disquetes) con una de las versiones de windows para IBM.
Y también pasó algo desapercibido un nuevo término que comenzó a usarse con cierta profusión en aquella época: la palabra ‘internetting‘ («interconexión») que al poco tiempo quedó en «internet» y fue como comenzó a conocerse a la red de redes (en detrimento de Arpanet).
Y también pasó algo desapercibido un nuevo término que comenzó a usarse con cierta profusión en aquella época: la palabra ‘internetting‘ («interconexión») que al poco tiempo quedó en «internet» y fue como comenzó a conocerse a la red de redes (en detrimento de Arpanet).
Internet es fruto de varios proyectos desarrollados en Estados Unidos de forma paralela, en un principio sin llegar a entrar verdaderamente en contacto entre ellos y, de forma algo más coordinada al final, por la intervención de la agencia ARPA(siglas de Advanced Research Projects Agency , institución directamente vinculada al Departamento de Defensa de los EE.UU. creada en 1958 en respuesta al lanzamiento soviético del satélite Sputnik 2 tripulado por la perrita Laika).
Por ello, muchos autores la consideran fruto de un proyecto de investigación militar destinado a buscar soluciones de comunicación informática en plena “guerra fría”, contexto donde se vivía permanentemente bajo la amenaza de una guerra nuclear que afortunadamente no llegó a producirse. Lo cierto es que la participación de la administración norteamericana en este desarrollo fue vital, independientemente de los objetivos que la auspiciasen. Contribuyó durante bastante tiempo al desarrollo de la verdadera infraestructura de red, algo que tuvo lugar unos cuantos años más tarde.
Operadores trabajando en un ordenador «mainframe», años 60.
Dos eran los objetivos que seguían estos grupos de trabajo. Hasta ese momento, los sistemas informáticos funcionaban generalmente en entornos mainframes, en los cuales se centralizaban todos los procesos en el ordenador principal, al mismo tiempo que la gestión y el almacenamiento de los datos. Los terminales que se usaban para interaccionar con ellos no eran ordenadores como los que usamos hoy en día, sino simples consolas de comunicaciones con reducidas capacidades de proceso de datos. Transformar esa idea de sistema centralizado en una metáfora de sistema descentralizado donde todas las estaciones de trabajo pudieran acceder a datos y programas y tuvieran cierta capacidad de proceso (que no fueran unos simples terminales de comunicaciones, sino ordenadores), representaba una nueva idea que vino a plasmarse años después: la de red de ordenadores, independientemente de su alcance.
Este cambio, por sí mismo, es trascendental y constituye la base de los sistemas de comunicaciones actuales. En este nuevo paradigma es donde se encuentran los vínculos con proyectos de investigación militares: el sistema centralizado es más vulnerable que un sistema descentralizado y la defensa estratégica estadounidense necesitaba de otros modos de comunicación.
En realidad, el sistema descentralizado también podía llegar a ser vulnerable (hay que recordar que el mundo vivía entonces en plena psicosis de posible guerra nuclear) por lo que Paul Baran (1964) llegó a proponer una red de conmutación de paquetes para comunicación vocal segura en el ámbito militar en un entorno distribuido. Sobre esa idea, y unos cuantos años más tarde, se concibió Arpanet si bien el proyecto de Baran ya había sido cerrado para entonces por RAND Corporation, el laboratorio de ideas de las fuerzas armadas norteamericanas.
Baran explicando en RAND su proyecto de red «galáctica».
El segundo objetivo que concentró una gran cantidad de esfuerzos de los investigadores fue cambiar el modo en el que podrían dialogar los ordenadores entre sí (una vez conectados), abandonando la tradicional conmutación de circuitos (que precisaba del establecimiento de la llamada y de la ocupación de todo un circuito de datos para la transmisión) e implementando la conmutación de paquetes de datos (donde no se tiene que esperar al establecimiento de la llamada y cada paquete transmitido procura aprovechar al máximo la capacidad del enlace). Esto permitió a los equipos informáticos compartir datos y aplicaciones en tiempo real. Ambas ideas estaban predestinadas a confluir en la creación de algo importante, como así fue.
Son dos también las fases en las que se podría dividir esta época. De 1961 a 1965 podemos hablar de planteamientos teóricos, siendo el más destacado el de la “Red Galáctica” de Licklider quien presentó su idea de red interconectada globalmente por medio de la cual cada uno pudiera acceder desde cualquier lugar a datos y programas (el concepto era muy parecido a la internet actual, aunque entonces era un sueño). Desde 1965 entramos en la primigenia conexión de dos equipos informáticos que llevó a cabo Roberts para verificar que la conmutación de circuitos no servía para sus propósitos. La segunda etapa coincide con su incorporación a ARPA en 1966 para desarrollar el concepto de red de ordenadores, idea que plasma en un proyecto denominado Arpanet presentado en una conferencia científica donde se percatan de que otros grupos de trabajo habían conseguido avances importantes en este campo.
A partir de ahí se suceden los avances y en septiembre de 1969 se elige al ordenador del equipo de Kleinrock como el primer IMP (“procesador de mensajes de interfaz”) y desde ese equipo, un mes más tarde, se envía el primer mensaje a otro ordenador del SRI (algunos participantes en el proyecto han comentado recientemente que la segunda letra de la palabra “Hi” no llegó nunca a California). Después se añadieron dos nodos en la Universidad de California, Santa Bárbara, y en la Universidad de Utah. De esta manera, acabando 1969, cuatro ordenadores (“hosts” en la jerga de la red; estos ordenadores pueden ser al mismo tiempo clientes y servidores) estaban conectados a la Arpanet inicial.
Hoy en día usamos la expresión “nativos digitales” para referirnos a las personas que han crecido con internet y la usan permanentemente con una habilidad consumada. Estas personas sienten atracción por todo lo relacionado con las TIC por medio de las cuales cubren una buena parte de sus necesidades de entretenimiento, diversión, comunicación, información y, tal vez, de formación.
Ordenadores de los años 70
Para estas personas, conocer que el primer mensaje de correo electrónico constaba de una palabra de dos letras: «Hi» y que fue enviado en octubre del año 1969 por Kleinrock desde el MIT(Instituto Tecnológico de Massachussets) al Network Information Centerde la Universidad de Stanford, puede resultar increíble a la par que paradójico, pudiendo llegar a ser para ellos bastante complicado aceptar que internet ya existía cuando sus padres iban al instituto, cuando The Beatles era aún un grupo de música en activo que acababa de editar el disco “Yellow Submarine”, la famosa Guerra de Vietnam estaba en su apogeo, el Muro de Berlín seguía en su sitio (sin graffiti alguno y con muchos guardias), en los Juegos Olímpicos, de forma repetitiva (a veces apabullante) atletas «amateurs» de un país llamado CCCP(siglas en cirílico de Союз Советских Социалистических Республик, la antigua Unión Soviética) ganaban montones de medallas cada cuatro años.
Cubierta y parte trasera del LP «Yellows Submarine» de The Beatles
Y sin embargo, parafreseando a Galileo: «todo eso es cierto«.